



15/06/2022
En el Grupo CaixaBank, diariamente, se ejecutan cientos de modelos de scoring, prevención de fraude, clasificación y segmentación de usuarios, análisis o clasificación de texto…, algunos de ellos en real time. En total, se da servicio y soporte a la operación financiera y comercial a los más de 20 millones de clientes del banco.
La operación de estos modelos, una vez desarrollado por nuestros excelentes equipos de data scientists, contiene altos requerimientos técnicos de confiabilidad, robustez y trazabilidad. MLOPS nos proporciona un framework para asegurar que se cumplen esos requerimientos.
A continuación, veremos los conceptos básicos de machine learning y MLOPS.
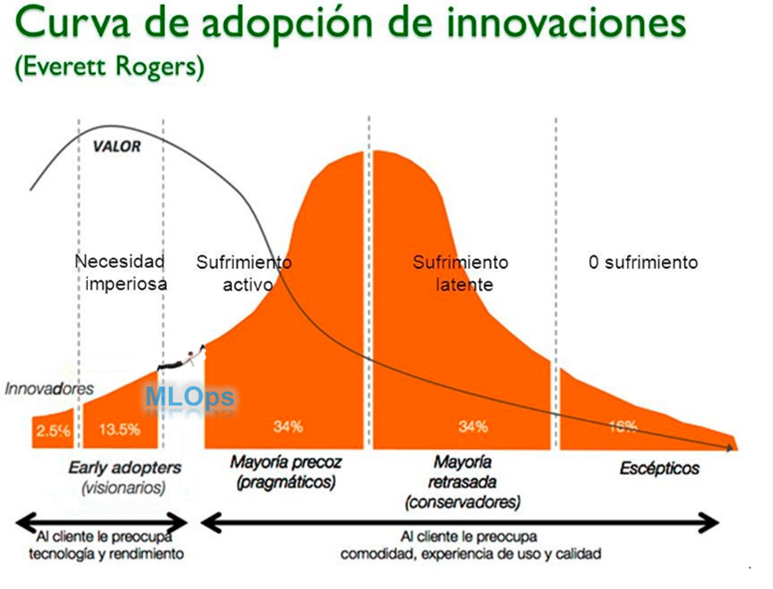
Los conceptos machine learning (ML) e inteligencia artificial (IA) ya han pasado a formar parte de nuestra vida. Pero esto ¿qué significa exactamente?
Llevamos siglos acumulando datos sobre, por ejemplo, el tiempo para intentar predecir si el próximo mes lloverá o hará sol. En función del lugar geográfico en el que vivimos, la historia de nuestros antepasados, etc., obtenemos unas conclusiones u otras. Sean las predicciones mejores o peores, solo existe una cierta probabilidad de «acertar» el resultado y cuando llega el día, la semana o el mes, podemos verificar el resultado y aprender para mejorar las futuras predicciones.
Pues bien, si los razonamientos los escribimos en el lenguaje de las máquinas, escribimos cómo tienen que transformar los datos, cómo calcular la precisión de un resultado y cómo comparar el resultado de la predicción con lo que ha ocurrido en la realidad, tenemos la definición de ML e IA. Sin embargo, esto que nosotros hacemos constantemente en cada decisión que tomamos sin darnos cuenta, que ya está automatizado en nuestro día a día, queremos llevarlo a un mundo industrial, que sea repetible, que sea automático, que sea escalable y que tome decisiones acerca de si debe cambiar la estructura del pensamiento porque la realidad se aleja de cómo en nuestra mente se había generado el resultado.
Desmitificando Términos
En este mundo se han acuñado muchos términos que suenan en el día a día, pero ¿qué significan?
- Data drift: supongamos el caso de un esquimal que lleva toda su vida generando un modelo mental de cuándo debe salir con paraguas y se traslada a vivir al trópico. A la hora de decidir si tiene que salir a la calle con paraguas, cuando las condiciones son tan sumamente distintas a las que tenía cuando generó su modelo, eso se llama data drift.
- Falsos positivos: si miro al pasado, de las 10 predicciones que hice que debía llevar paraguas y lo llevé, en cuántas no acerté. De igual modo existen falsos negativos, verdaderos positivos y verdaderos negativos. En definitiva, son los datos en los que nos basamos para calcular el accuracy o precisión.
- Accuracy: el porcentaje resultante de calcular de cada 10 veces que salgo a la calle y llevo paraguas, cuántas realmente he acertado y no me he mojado. Mide lo fiable que es mi modelo a la hora de predecir.
- Model monitoring: quizás este sea uno de los términos más importantes, porque es el que trata de decidir en qué momento el modelo deja de ser fiable, qué tengo que hacer en ese momento. En el traslado al trópico, debo sustituir un modelo por otro, debo generar resultados con ambos e ir comparando, un día uno y otro día otro hasta que demuestre que el nuevo es mejor.
Todo este set de términos tan chulos, y otro sinfín de ellos, tratan de expresar en el mundo modelos de confianza que puedo tener en las predicciones para tomar decisiones y describir los motivos y tiempos en los que dicha confianza se pierde.
Sin querer entrar en el mundo de los datos, sí es importante destacar que es la base primordial para que las decisiones sean buenas, por lo que es importante conocer lo que se denomina la predictibilidad de una variable. Es decir, «el dolor de cadera» es una variable predictiva mientras el dolor no sea perenne o no haya existido nunca, en que deja de ser predictiva. En definitiva, encontrar la información adecuada, recopilarla, tratarla «como debe ser»… Que todos los tipos de información posibles estén representados (sesgo) es de vital importancia para que podamos vivir tranquilos con nuestras decisiones basadas en predicciones.
¿Quién es Quién?
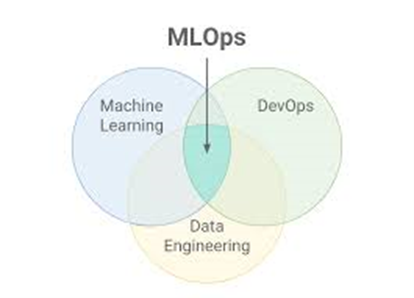
Una vez que hemos aclarado los conceptos, vamos al mundo industrial:
--> DataOps se encarga de acumular los datos, automatizar su tratamiento y prepararlos para la toma de decisión. Se centra en disponibilizar el mejor dato y del mejor modo posible.
--> MLOps se encarga de generar los razonamientos, aplicarlos, calcular las posibilidades y evaluar la fiabilidad del resultado. Se centra en consumir el dato del mejor modo posible.
Entre ambos tratan de contribuir en tiempo y forma a servir al negocio el mejor dato posible para la toma de decisiones. Cada disciplina genera material suficiente para un artículo; en el presente centraremos nuestros esfuerzos en MLOps.
MLOps se enfoca en la operativización (DevOps) de los modelos de aprendizaje automático (ML), por tanto se trata de aunar bajo un mismo paradigma ambos conceptos. Si bien la teoría parece simple, no lo es en la práctica.
Durante los últimos años se han puesto en producción múltiples desarrollos de software. Se han generado ingentes cantidades de artículos, metodologías, sistemáticas y pruebas sobre cómo se debe hacer esto; por lo tanto, se puede afirmar que el mundo DevOps es un mundo maduro en el que se cuenta con:
1. Estandarizaciones de nomenclaturas
2. Pipelines para el despliegue
3. Definición de pruebas de software
4. Modelos de testeo
5. Modelos de monitorización
Un software se desarrolla, se configuran los pipelines de despliegue, se realizan pruebas estándares y, pasándolo por distintos entornos, llega a producción. Salvo que la monitorización arroje algún error o se desarrollen nuevos evolutivos, ni el software ni el modelo de trabajo cambiarán.
A este mundo llega un nuevo inquilino, en el que la misión principal de los data scientist (DS) no es desarrollar un software, sino comprender los datos y fabricar nuevos insights. De la mano de este nuevo componente que se une al club, vienen nuevas formas de trabajar y tenemos que buscar las sinergias. En este escenario es donde nacen las nuevas disciplinas DataOps y MLOps, que vienen con nuevos perfiles bajo el brazo: Data Engineer y MLEngineer.
El reto
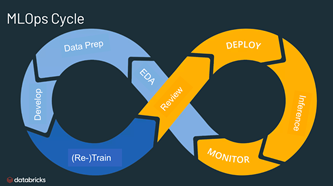
El reto al que se enfrentan estos nuevos perfiles es el de aunar bajo un nuevo paradigma:
DevOps es un mundo rígido que intenta mantener siempre bajo control las operaciones, pensando que es posible establecer todas las condiciones a priori, es decir, que definido un software ante una misma entrada siempre se va a producir la misma salida.
Data y ML es un mundo cambiante con gran evolución y que no atiende a la búsqueda de la estabilidad en el software, sino a la generación de los nuevos valores.
Centrándonos en MLOps, el ML Engineer tiene como misión definir cómo estos mundos deben convivir. Para ello, debe contarse con conocimientos en ingeniería de software, ML y Ops.
Serán:
Ingenieros de software que han aprendido acerca de los modelos de ML y son capaces de automatizarlos.
DS que han adquirido los principios de desarrollo de software, estructuran el software y son capaces de automatizar los modelos.
Intervinientes en ML
- Datos, obviando el método por el que se generan. Siempre debemos estar atentos a cómo varían los datos con los que tomamos nuestras decisiones.
- Algoritmos, el modo en el que se procesan los datos para generar un entrenamiento.
- Software, el proceso que define el flujo (pipeline) que se produce para generar la predicción.
- Modelo, el resultado de aplicar a los datos el algoritmo en un pipeline y que servirá para generar las predicciones.
- Monitorización, qué tan bien se comporta el modelo en relación con los datos de entrada y los resultados reales.
Ciclo de vida
Anteriormente hemos sentado las bases necesarias para el ML. Veamos cómo hasta ahora se creaba y se ponía en producción un modelo.
La petición
Una de las unidades de ventas quiere lanzar una campaña en la que regala un paraguas si abres una cuenta en un día lluvioso y quieren generar un stock de paraguas suficiente. Para calcular las unidades que deberán fabricar, piden una previsión de los días lluviosos en los próximos 6 meses a partir de enero. El reparto se irá generando diariamente según la predicción meteorológica para el día siguiente.
El desarrollo/experimentación
Esta fase se centra en los datos de entrada, el algoritmo y el modelo, desatendiendo en gran medida el software y la monitorización.
Nos llega la petición y debemos tener listo el modelo en producción el día 1 de enero.
- Para calcular el promedio de días lluviosos en los primeros 6 meses del año, nos basamos en datos históricos y, mediante métodos estadísticos, realizamos una predicción aproximada del número de días lluviosos y las contrataciones de cuentas en días lluviosos, y se genera un stock aproximado redondeando al alza.
- Para generar la distribución del reparto, se generará un modelo predictivo basado en series temporales, la predicción del tiempo, la afluencia a la oficina en días lluviosos, la probabilidad de contratación, etc.
Es necesario decir que la fase de experimentación tiene gran dependencia de los datos históricos, con lo que se debe garantizar que esta fase se produce con datos que representan fielmente la distribución de los datos de producción.
Para resolver la segunda parte, en la queremos generar el modelo predictivo, establecemos una sistemática de trabajo:
- Preparamos los datos de entrenamiento del modelo con datos históricos, con los que ya conocemos la contratación en días lluviosos.
- Tomamos una parte representativa de los datos para el entrenamiento y el resto los dejamos para validar los resultados.
- Introducimos los datos en un algoritmo, que genera un aprendizaje.
- De los datos que habíamos reservado, quitamos el componente de si se produjo o no la contratación, los pasamos por el resultado del aprendizaje y generamos una predicción.
- Confrontamos los resultados del aprendizaje con los resultados reales y generamos un valor que indica la confiabilidad del modelo.
Este proceso se realiza iterativamente hasta que se consigue un indicador de confiabilidad suficientemente bueno como para continuar adelante con el proceso, es decir, hasta que estemos bastante seguros de que no nos vamos a confundir con la cantidad de paraguas que predecimos que serán necesarios para el día siguiente.
La industrialización
Esta fase se centra en el software y la monitorización. Se trata de estandarizar para que sea repetible, automatizable, escalable, monitorizable, mantenible, etc.
Al contrario que en la experimentación, la dependencia de los datos es mínima, bastará con hacer que los datos viajen según los flujos definidos sin generar errores inesperados.
Partiendo del experimento que se dio por bueno en la fase anterior y bajo los parámetros definidos por el DS, comienza un proceso de desarrollo de software.
- Entender el flujo.
- Implementar el flujo de entrenamiento.
- Implementar el flujo de predicción.
- Implementar el flujo de monitorización.
- Implementar la lógica de reentrenamiento.
- Implementar la lógica de puesta en producción.
- Integrar la monitorización de datos y modelos.
Para dar por concluida esta fase de desarrollo, se debe validar que todos los componentes juegan su papel en el momento en que es necesario y que los resultados que se obtienen son los esperados.
En el supuesto de que todo lo anterior tenga el OK, los datos, las monitorizaciones, el software, el modelo, etc., se podrá poner en producción.
La producción
Asumamos que todo está perfecto y conseguimos ponerlo en producción para el día 1 de enero. Tendremos en producción:
- Un software que es estable y que a partir de unos datos de entrada es capaz de generar una predicción.
- Un software que es estable y que a partir de una orden puede generar con el mismo algoritmo una nueva versión del modelo que aprende con los nuevos datos que se han ido generando, es decir, cambia el modo de pensar.
- Un software que es estable y que es capaz de comparar las predicciones con los datos reales y generar las métricas comparativas.
- Un software que es estable y que es capaz de medir cuándo los datos que utilizamos para predecir y los resultados se están alejando de lo esperado.
Puesto que el proceso se ejecuta diariamente, en primer lugar se debe evaluar si las predicciones y la realidad están suficientemente cercanos, es decir, si puedo seguir concluyendo como lo hacía antes. En caso de que esto no sea así será porque las condiciones de contorno han cambiado. Deberemos, entonces, lanzar una petición que genere un nuevo modelo y se valide si ofrecerá mejores predicciones que el actual. Si de nuevo la respuesta es afirmativa, se sustituirá uno por otro, dejando registrado el cambio.
Curiosamente, todas estas modificaciones se han producido bajo los paradigmas establecidos por DevOps: «Un software se desarrolla, se configuran los pipelines de despliegue, se realizan pruebas estándares y, pasando por distintos entornos, llega a producción. Salvo que la monitorización arroje algún error o se desarrollen nuevos evolutivos, ni el software ni el modelo de trabajo cambiarán.»
Conclusiones
La madurez de las organizaciones viene dada por la fluidez con la que se ejecute el ciclo de vida. El papel de los ML Engineer es el de implantar en las organizaciones este nuevo paradigma. Por lo tanto:
– Deben aportar a los DS conocimientos y mecanismos propios del ciclo de vida del software que acorten la etapa de industrialización.
– Deben aportar herramientas que permitan a los DS centrarse en sus desarrollos sin necesidad de imbuirse en el mundo de la ingeniería de software, pero que por el contrario sigan las mejores praxis definidas para este.
– Deben proporcionar a DevOps los conocimientos y mecanismos propios a través de los que se garantice la estabilidad del software que se pone en producción.
– Deben aportar herramientas que permitan a DevOps centrarse en las operaciones sin necesidad de imbuirse en el mundo de la IA, pero que por el contrario sigan las mejores praxis definidas para este.
El peor enemigo de la evolución es la incertidumbre. ¿Estarías dispuesto a montar en un coche autónomo? Nuestra misión es aportar la confiabilidad y generar un entorno amigable en todos los ámbitos y que los entornos industriales permitan que también el software sea autónomo.
Sugiero una pregunta: mañana, ¿saldrás con paraguas?
¿Qué hacemos en CaixaBank Tech?
Nos estamos subiendo al futuro del ML industrializado incorporando estándares de la industria y generando nuestros propios frameworks, que respetan las reglas presentes del ML y garantizan la adaptabilidad a los futuros marcos regulatorios y éticos. Desde el área de Analítica Avanzada de CaixaBank Tech, buscamos generar un marco de trabajo escalable, mantenible y sostenible, que minimice el impacto de nuestra huella con la optimización de nuestros procesos.
tags:
Comparte:




