



15/06/2022
Al Grup CaixaBank, diàriament, s’executen centenars de models de scoring, prevenció de frau, classificació i segmentació d’usuaris, anàlisi o classificació de text..., alguns dels quals en real time. En total, es dona servei i suport a l’operació financera i comercial als més de 20 milions de clients del banc.
L’operació d’aquests models, una vegada desenvolupat pels nostres excel·lents equips de data scientist, conté alts requeriments tècnics de confiabilitat, robustesa i traçabilitat. MLOPS ens proporciona un framework per assegurar que es compleixen aquests requeriments
A continuació, veurem els conceptes bàsics de machine learning i MLOPS.
Els conceptes machine learning (ML) i intel·ligència artificial (IA) ja han passat a formar part de la nostra vida. Però això, què significa exactament?
Fa segles que acumulem dades, per exemple, sobre el temps per intentar predir si el mes que ve plourà o farà sol. En funció del lloc geogràfic en el qual vivim, la història dels nostres avantpassats, etc., obtenim unes conclusions o unes altres. Siguin les prediccions millors o pitjors, només hi ha una certa probabilitat d’«encertar» el resultat i quan arriba el dia, la setmana o el mes, podem verificar el resultat i aprendre per millorar les futures prediccions.
Doncs bé, si els raonaments els escrivim en el llenguatge de les màquines, escrivim com han de transformar les dades, com han de calcular la precisió d’un resultat i com cal comparar el resultat de la predicció amb el que ha ocorregut en la realitat, tenim la definició de ML i IA. Tanmateix, això que nosaltres fem constantment en cada decisió que prenem sense adonar-nos-en, que ja està automatitzat en el nostre dia a dia, volem portar-ho a un món industrial, que sigui repetible, que sigui automàtic, que sigui escalable i que prengui decisions sobre si ha de canviar l’estructura del pensament perquè la realitat s’allunya de com en la nostra ment s’havia generat el resultat.
Desmitificant termes
En aquest món s’han encunyat molts termes que sonen en el dia a dia, però, què volen dir?
- Data drift: suposem el cas d’un esquimal que s’ha passat la vida generant un model mental de quan ha de sortir amb paraigua i es trasllada a viure al tròpic. A l’hora de decidir si ha de sortir al carrer amb paraigua, quan les condicions són tan summament diferents de les que tenia quan va generar el model, això es diu data drift.
- Falsos positius: si miro al passat, de les 10 prediccions que vaig fer que havia de portar paraigua i el vaig portar, en quantes no vaig encertar. De la mateixa manera, hi ha falsos negatius, veritables positius i veritables negatius. En definitiva, són les dades en les quals ens basem per calcular l’accuracy o precisió.
- Accuracy: el percentatge resultant de calcular de cada 10 vegades que surto al carrer i porto paraigua, quantes realment l’he encertat i no m’he mullat. Mesura la fiabilitat del model a l’hora de predir.
- Model monitoring: potser aquest és un dels termes més importants, perquè és el que tracta de decidir en quin moment el model deixa de ser fiable, què haig de fer aleshores. En el trasllat al tròpic, haig de substituir un model per un altre, haig de generar resultats amb tots dos i anar comparant, un dia un i un altre dia l’altre fins que demostri que el nou és millor.
Tot aquest conjunt de termes tan vistosos, i encara n’hi ha molts més, miren d’expressar en el món models de confiança que puc tenir en les prediccions per prendre decisions i descriure els motius i els temps en els quals aquesta confiança es perd.
Sense voler entrar en el món de les dades, sí que és important destacar que és la base primordial perquè les decisions siguin bones, per la qual cosa és important conèixer el que es denomina la predictibilitat d’una variable. És a dir, «el mal al maluc» és una variable predictiva mentre el dolor no sigui perenne o no hagi existit mai, en què deixa de ser predictiva. En definitiva, trobar la informació adequada, recopilar-la, tractar-la «com ha de ser»… Que tots els tipus d’informació possibles estiguin representats (biaix) és de vital importància perquè puguem viure tranquils amb les nostres decisions basades en prediccions.
Qui és qui?
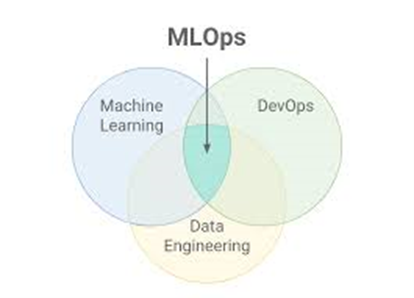
Una vegada que hem aclarit els conceptes, anem al món industrial:
--> DataOps s’encarrega d’acumular les dades, automatitzar-ne el tractament i preparar-les per a la presa de decisió. Se centra a disponibilitzar la millor dada i de la millor manera possible.
--> MLOps s’encarrega de generar els raonaments, aplicar-los, calcular les possibilitats i avaluar la fiabilitat del resultat. Se centra a consumir la dada de la millor manera possible.
Entre tots dos tracten de contribuir dins del termini i en la forma escaient a servir al negoci la millor dada possible per a la presa de decisions. Cada disciplina genera material suficient per a un article; en el present centrarem els esforços en MLOps.
MLOps s’enfoca en l’operativització (DevOps) dels models d’aprenentatge automàtic (ML), per tant, es tracta de conjuminar sota un mateix paradigma tots dos conceptes. Si bé la teoria sembla simple, no ho és a la pràctica.
Durant els últims anys s’han posat en producció múltiples desenvolupaments de programari. S’han generat quantitats ingents d’articles, metodologies, sistemàtiques i proves sobre com s’ha de fer això, per tant, es pot afirmar que el món DevOps és un món madur en el qual es disposa de:
1. Estandarditzacions de nomenclatures
2. Pipelines per al desplegament
3. Definició de proves de software
4. Models de testatge
5. Models de monitoratge
Un software es desenvolupa, es configuren els pipelines de desplegament, es fan proves estàndards i, passant-ho per diferents entorns, arriba a producció. Tret que el monitoratge llanci algun error o es desenvolupin nous evolutius, ni el software ni el model de treball no canviaran.
A aquest món arriba un nou inquilí, en el qual la missió principal dels data scientist (DS) no és desenvolupar un programari sinó comprendre les dades i fabricar nous insights. Gràcies a aquest nou component que s’uneix al club, venen noves maneres de treballar i hem de buscar les sinergies. En aquest escenari és on neixen les noves disciplines DataOps i MLOps, que venen amb nous perfils sota el braç: Data Engineer i MLEngineer.
El repte
El repte al qual s’enfronten aquests nous perfils és unir sota un nou paradigma:
- DevOps: és un món rígid que intenta mantenir sempre sota control les operacions, pensant que és possible establir totes les condicions a priori, és a dir, que, definit un programari davant una mateixa entrada, sempre es produirà la mateixa sortida.
- Data i ML: és un món canviant amb gran evolució i que no atén la cerca de l’estabilitat en el programari, sinó la generació dels nous valors.
Centrant-nos en MLOps, el ML Engineer té com a missió definir com aquests mons han de conviure. Per fer-ho, cal tenir coneixements d’enginyeria de programari, ML i Ops.
Seran:
- Enginyers de software que han après sobre els models de ML i són capaços d’automatitzar-los.
- DS que han adquirit els principis de desenvolupament de software, estructuren el software i són capaços d’automatitzar els models.
Intervinents en ML
- Dades, obviant el mètode pel qual es generen. Sempre hem d’estar atents a com varien les dades amb les quals prenem les nostres decisions.
- Algoritmes, la manera en què es processen les dades per generar un entrenament.
- Programari, el procés que defineix el flux (pipeline) que es produeix per generar la predicció.
- Model, el resultat d’aplicar a les dades l’algoritme en un pipeline i que servirà per generar les prediccions.
- Monitoratge, com es comporta de bé el model en relació amb les dades d’entrada i els resultats reals.
Cicle de vida
Anteriorment hem establert les bases necessàries per al ML. Vegem com fins ara es creava i es posava en producció un model.
La petició
Una de les unitats de vendes vol llançar una campanya en la qual regala un paraigua si obres un compte en un dia plujós i volen generar un estoc de paraigües suficient. Per calcular les unitats que hauran de fabricar, demanen una previsió dels dies plujosos en els 6 mesos vinents a partir del gener. El repartiment es generà diàriament segons la predicció meteorològica per a l’endemà.
El desenvolupament / experimentació
Aquesta fase se centra en les dades d’entrada, l’algoritme i el model, de manera que es desatén, en gran manera, el programari i el monitoratge.
Ens arriba la petició i hem de tenir llest el model en producció el dia 1 de gener.
- Per calcular la mitjana de dies plujosos els primers 6 mesos de l’any, ens basem en dades històriques i, mitjançant mètodes estadístics, fem una predicció aproximada del nombre de dies plujosos i les contractacions de comptes en dies plujosos per generar un estoc aproximat arrodonint a l’alça.
- Per generar la distribució del repartiment, es generarà un model predictiu basat en sèries temporals, la predicció del temps, l’afluència a l’oficina en dies plujosos, la probabilitat de contractació, etc.
Cal dir que la fase d’experimentació té una gran dependència de les dades històriques, amb la qual cosa s’ha de garantir que aquesta fase es produeix amb dades que representen fidelment la distribució de les dades de producció.
Per resoldre la segona part, en què volem generar el model predictiu, establim una sistemàtica de treball:
- Preparem les dades d’entrenament del model amb dades històriques amb les quals ja coneixem la contractació en dies plujosos.
- Prenem una part representativa de les dades per a l’entrenament i la resta les deixem per validar els resultats.
- Introduïm les dades en un algoritme, que genera un aprenentatge.
- De les dades que havíem reservat, en traiem el component de si es va produir la contractació o no, les passem pel resultat de l’aprenentatge i generem una predicció.
- Confrontem els resultats de l’aprenentatge amb els resultats reals i generem un valor que indica la confiabilitat del model.
Aquest procés es fa iterativament fins que s’aconsegueix un indicador de confiabilitat prou bo per tirar endavant amb el procés, és a dir, fins que estiguem força segurs que no ens confondrem amb la quantitat de paraigües que prediem que seran necessaris per a l’endemà.
La industrialització
Aquesta fase se centra en el software i el monitoratge. Es tracta d’estandarditzar perquè sigui repetible, automatitzable, escalable, monitoritzable, mantenible, etc.
Al contrari que en l’experimentació, la dependència de les dades és mínima, n’hi haurà prou fent que les dades viatgin segons els fluxos definits sense generar errors inesperats.
Partint de l’experiment que es va donar per bo a la fase anterior i sota els paràmetres definits pel DS, comença un procés de desenvolupament de software.
- Entendre el flux.
- Implementar el flux d’entrenament.
- Implementar el flux de predicció.
- Implementar el flux de monitoratge.
- Implementar la lògica de reentrenament.
- Implementar la lògica de posada en producció.
- Integrar la monitoratge de dades i models.
Per donar per conclosa aquesta fase de desenvolupament, cal validar que tots els components duen a terme el seu paper en el moment en què és necessari i que els resultats que s’obtenen són els esperats.
En el cas que tot això tingui l’OK, les dades, els monitoratges, el programari, el model, etc., es podrà posar en producció.
La producció
Assumim que tot està perfecte i aconseguim posar-ho en producció per al dia 1 de gener. Tindrem en producció:
- Un programari que és estable i que sobre la base d’unes dades d’entrada és capaç de generar una predicció.
- Un programari que és estable i que sobre la base d’una ordre pot generar amb el mateix algoritme una nova versió del model que aprèn amb les noves dades que s’han generat, és a dir, canvia la manera de pensar.
- Un programari que és estable i que és capaç de comparar les prediccions amb les dades reals i generar les mètriques comparatives.
- Un programari que és estable i que és capaç de mesurar quan les dades que utilitzem per predir i els resultats s’allunyen del que és esperable.
Com que el procés s’executa diàriament, en primer lloc s’ha d’avaluar si les prediccions i la realitat estan prou pròxims, és a dir, si puc continuar traient-ne conclusions com ho feia abans. En cas que no sigui així, és perquè les condicions de contorn han canviat. Aleshores, haurem de llançar una petició que generi un nou model i es validi si oferirà millors prediccions que l’actual. Si la resposta torna a ser afirmativa, se substituirà l’un per l’altre i caldrà deixar registrat el canvi.
Curiosament, totes aquestes modificacions s’han produït sota els paradigmes establerts per DevOps: «Un programari es desenvolupa, es configuren els pipelines de desplegament, es fan proves estàndards i, passant per diferents entorns, arriba a producció. Tret que el monitoratge llanci algun error o es desenvolupin nous evolutius, ni el software ni el model de treball no canviaran.»
Conclusions
La maduresa de les organitzacions ve donada per la fluïdesa amb la qual s’executa el cicle de vida. El paper dels ML Engineer és implantar en les organitzacions aquest nou paradigma. Per tant:
– Han d’aportar als DS coneixements i mecanismes propis del cicle de vida del software que escurcin l’etapa d’industrialització.
– Han d’aportar eines que permetin als DS centrar-se en els seus desenvolupaments sense necessitat d’imbuir-se en el món de l’enginyeria de programari, però que, per contra, segueixin les millors praxis definides per a aquest.
– Han de proporcionar a DevOps els coneixements i els mecanismes propis a través dels quals es garanteixi l’estabilitat del programari que es posa en producció.
– Han d’aportar eines que permetin a DevOps centrar-se en les operacions sense necessitat d’imbuir-se en el món de la IA, però que per contra segueixin les millors praxis definides per a aquest.
El pitjor enemic de l’evolució és la incertesa. Estaries disposat a pujar en un cotxe autònom? La nostra missió és aportar la confiabilitat i generar un entorn amigable en tots els àmbits i que els entorns industrials permetin que també el programari sigui autònom.
Suggereixo una pregunta: demà, sortiràs amb paraigua?
Què fem a CaixaBank Tech?
Ens estem pujant al futur del ML industrialitzat incorporant estàndards de la indústria i generant els nostres propis frameworks, que respecten les regles presents del ML i garanteixen l’adaptabilitat als futurs marcs reguladors i ètics. Des de l’àrea d’Analítica Avançada de CaixaBank Tech busquem generar un marc de treball sostenible, escalable, mantenible i sostenible, que minimitzi l’impacte de la nostra petjada ambiental amb l’optimització dels nostres processos.
tags:
Comparteix:




