



14/02/2024
Descubre qué es la IA Generativa, cómo funciona y sus principales diferencias de la IA tradicional en este blog.
2023 ha sido, indudablemente, el año de la Inteligencia Artificial Generativa (IAG). Se han producido numerosos avances destacables en este ámbito y, a lo largo del año, han ido saliendo noticias sobre cómo la IA generativa nos puede ayudar en nuestro día a día y los riesgos que conlleva.
Pero ¿Sabemos qué es la IA Generativa y la diferencia que hay con los modelos de IA tradicional?
¡No te pierdas la oportunidad de adentrarte en el emocionante universo de la Inteligencia Artificial Generativa (IAG)! Si quieres descubrir cómo esta innovadora tecnología va a transformar nuestra rutina en 2024, ¡sigue leyendo!
IA Tradicional vs. IA Generativa, ¿Cuáles son sus principales diferencias?
Explorar las diferencias entre la IA Tradicional y la IA Generativa es esencial para comprender la evolución tecnológica. La IA tradicional se basa en algoritmos predefinidos y datos históricos para realizar tareas específicas, mientras que la IA Generativa va más allá, creando contenido original y adaptándose a nuevas situaciones de manera creativa.
Los modelos de IA tradicionales se basan en algoritmos que siguen unas reglas predefinidas y que están pensados para resolver tareas específicas, pero no pueden generalizar ni adaptarse a nuevos contextos. En cambio, la Inteligencia Artificial Generativa es una rama de la inteligencia artificial que se centra en la generación de contenidos (nuevo y original), como imágenes, texto, música, procesamiento de voz, vídeo, etc. La IAG utiliza técnicas de aprendizaje automático y redes neuronales para crear modelos capaces de generar contenido similar al que se encuentra en conjuntos de datos de entrenamiento.
¿Cómo funciona la Inteligencia Artificial Generativa?
El funcionamiento de la Inteligencia Artificial Generativa varía según el enfoque utilizado, pero, a menudo, se basa en el uso de redes neuronales con arquitectura Transformer.
Arquitectura transformer: La arquitectura Transformer está pensada para que los modelos de IA vayan aprendiendo relaciones relevantes entre las diferentes partes que componen los datos de entrada (por ejemplo, entre las palabras que forman el texto de entrada de un modelo de generación de texto) y las utilicen para producir un resultado a partir de ellas.
Por ejemplo, un modelo como chat GPT, “calcula” las relaciones entre las palabras que componen las instrucciones que se le pasen y genera texto concatenando las palabras que le parecen más probables a partir de este patrón de relaciones.
Esta arquitectura, junto con el mecanismo de “Reinforcement Learning from Human Feedback”, que explicamos más adelante, conforman los dos pilares fundamentales que han abierto el camino hacia los “Large Language Models” LLMs, tal como los conocemos hoy en 2024.
¿Qué son los LLMs, para qué sirven y cómo funcionan?
Los Large Language Models (LLMs) o modelos de lenguaje de gran escala son sistemas de inteligencia artificial diseñados para comprender y generar lenguaje simulando el comportamiento humano. Estos modelos son entrenados utilizando conjuntos de técnicas de aprendizaje automático, especialmente el aprendizaje profundo, con gran cantidad de datos.
El funcionamiento de los LLM se basa en redes neuronales y, casi en la totalidad de los casos, en arquitectura “Transformers”, como el modelo GPT-3 (Generative Pre-trained Transformer 3), desarrollado por OpenAI.
Estos modelos están compuestos por múltiples capas de unidades de procesamiento que se interconectan y aprenden a través de millones o, incluso, miles de millones de ejemplos de texto.
¿Cómo se entrenan los LLM?
Durante el entrenamiento, los LLM se entrenan con grandes cantidades de texto, libros, artículos de noticias, páginas web y otros recursos disponibles en la web. Utilizando técnicas de procesamiento del lenguaje natural y aprendizaje supervisado, los modelos aprenden patrones, relaciones y estructuras del lenguaje, así como la capacidad de predecir la siguiente palabra dado un contexto.
Para utilizar un LLM, se le debe proporcionar un contexto o una entrada de texto, cuanto más rico sea el contexto más precisa será la respuesta del modelo. El modelo, por su parte, con los datos de entrada y en su conocimiento previo adquirido durante el entrenamiento generará una respuesta.
Los LLM son modelos estadísticos y no tienen una comprensión profunda ni del significado ni del contexto de los textos, con lo que puedan generar, en algunos casos, respuestas muy acertadas, pero también cometer errores y generar resultados incorrectos o incoherentes. Estas respuestas son las que llamamos alucinaciones. Además, los LLM también pueden cometer errores debido a sesgos inherentes en los datos de entrenamiento, lo que puede influir en los resultados generados.
Una vez que un LLM ha sido entrenado, puede utilizarse para realizar una amplia gama de tareas relacionadas con el lenguaje. Por ejemplo, puede utilizarse para completar oraciones o textos, responder preguntas, traducir texto de un idioma a otro, generar texto coherente y relevante, resumir documentos, entre otras aplicaciones.
Pero, también, puedan dar respuestas inapropiadas y, para ello, se pueden (y se deben) tomar diferentes medidas para que estos modelos sean “Helpful-Honest-Harmless“, es decir que proporcionen ayuda, siendo honestos e inocuos.
RLHF para obtener respuestas más acertadas y honestas
Pero ¿cómo podemos asegurarnos de que no son peligrosos y que se pueden liberar al público sin peligro?
El otro avance fundamental en el campo de la IA generativa, que ha permitido el desarrollo de modelos como el GPT 3.5, que son mucho más fiables de los que había anteriormente, es el mecanismo de reinforcement earning from human feedback (RLHF).
¿Cómo funciona el RLHF?
Para ello se le pasan preguntas y las respuestas generadas por el LLM a un grupo de personas que evaluarán si la respuesta es de calidad o si, por el contrario, incumple las normas. Esto retroalimenta al modelo mediante “premios o penalizaciones”, permitiendo reajustar sus parámetros gracias al Aprendizaje por refuerzo.
Más en detalle, para el RLHF se siguen 3 pautas para que los resultados devueltos por los modelos de IA se alineen mucho más con lo que se esperaría desde un agente humano:
- El modelo LLM se entrena con parejas de prompts (es decir, “instrucciones” que el modelo debe seguir para generar un output) y sus respectivos outputs esperados.
- Luego, para un conjunto extenso de prompts, se utiliza el modelo LLM para producir diferentes outputs para un mismo prompt y se le asigna una puntuación a cada output
- Finalmente, el set de respuestas y puntos se utiliza para entrenar un modelo de “reinforcement learning” que sesga el modelo LLM hacía respuestas que hubiesen recibido puntuación más alta al punto 2.
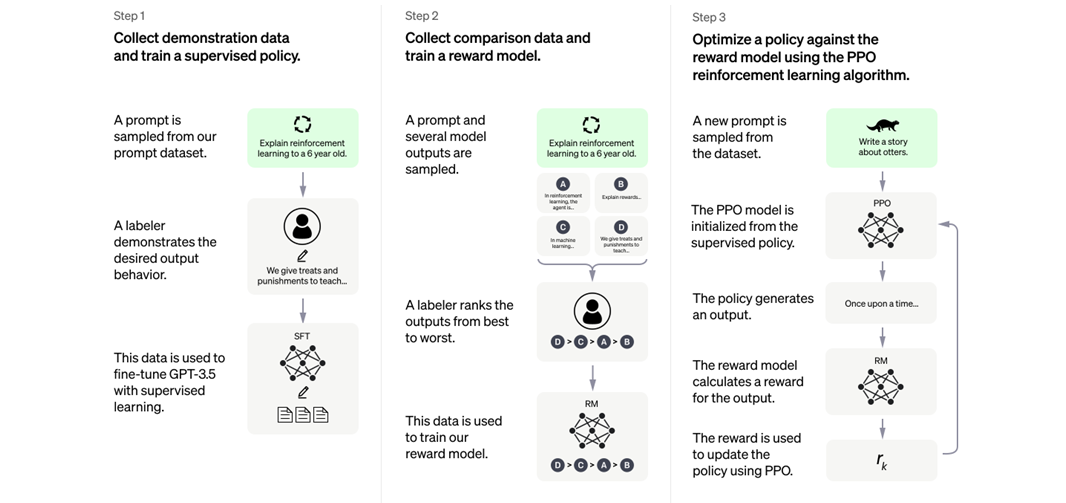
Diagrama que ilustra los tres pasos del RLHF. Fuente: OpenAI
Tabla comparativa sobre los LLMs más conocidos

Como podemos ver, cuánto más grandes son los modelos más capacidades tienen.
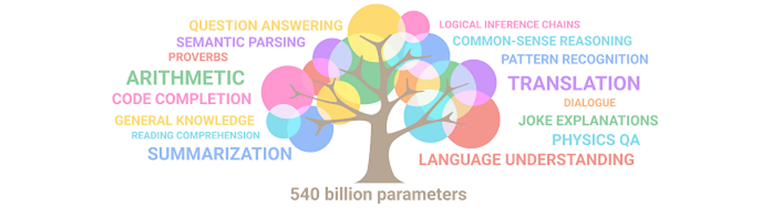
Ilustración de cómo emergen habilidades en un LLM conforme aumenta su tamaño. Fuente: Google.
¿Qué capacidades podemos encontrar en los modelos LLM?

Impulsando la Inteligencia Artificial generativa en CaixaBank con GenIAl
Desde CaixaBank Tech participamos activamente en el proyecto de GenIAl, que cuenta con más de 100 profesionales dedicados exclusivamente al análisis y desarrollo de aplicaciones con Inteligencia Artificial generativa.
Se trata de un equipo multidisciplinar que trabaja y evoluciona en un entorno de aprendizaje constante. Lo cierto es que, el acuerdo estratégico de colaboración que CaixaBank mantiene con Microsoft nos permite cocrear y acceder a modelos y avances tecnológicos que todavía no se encuentran disponibles en el mercado.
tags:
Comparte:




