




18/03/2023
At CaixaBank Group, hundreds of scoring, fraud prevention, user classification and segmentation, text analysis or classification models are run every day, some in real time. In total, service and support is provided to financial and commercial operation for more than 20 million bank customers.
After development by our excellent teams of data scientists, operation of these models includes high technical requirements in terms of reliability, robustness and traceability. MLOPS provides us with a framework to ensure compliance with those requirements.
The basic concepts of machine learning and MLOPS are set out below.
Machine learning (ML) and artificial intelligence (AI) concepts are now already part of our lives. But, what does this mean exactly?
For example, we have spent centuries gathering data about the weather to try and forecast whether it will rain next month or be sunny. Depending on where we live, the history of our ancestors, etc. we get certain findings or others. Whether they are better or worse forecasts, there is a certain probability of "guessing" the result and when the day, week or month comes, we can check the result and learn how to improve future forecasts.
Well, if we write the rationale in machine language, we write how to transform the data, how to calculate the precision of a result and how to compare the forecast result to what happened in reality - this is the definition of ML and AI. Nevertheless, this thing that what we do constantly in every decision we make without realising it, which is already automated in our everyday life, is what we want to transfer to the industrial sphere so that it can be repeatable, automatic and scalable, and decisions be made on whether how we think needs to change since reality is far removed from how the result was generated in our minds.
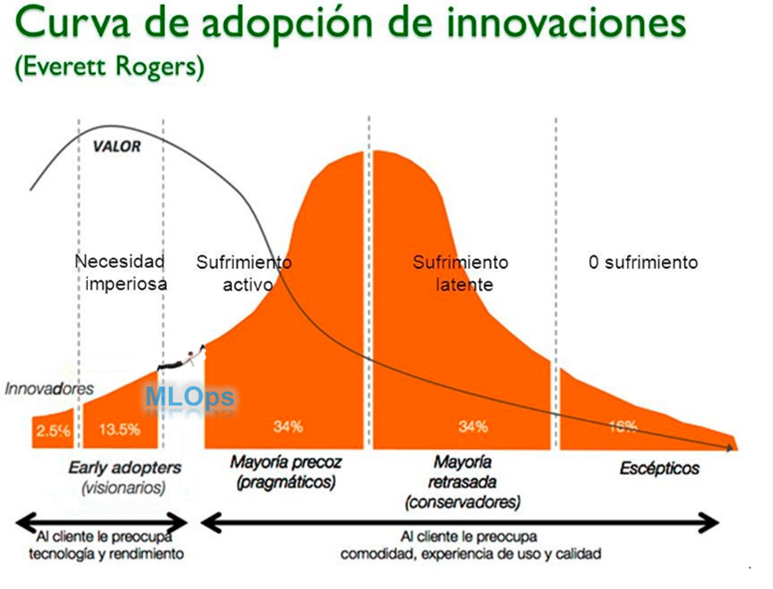
Demystifying terms
Many terms coined in this world are heard every day but, what do they mean?
- Data drift: let’s take the example of an Eskimo who has spent his entire life generating a mental model of when to take an umbrella to go out but then moves to the tropics. When deciding on whether he needs to head out with an umbrella, when the conditions are so different to those he knew when he generated his model, this is called data drift.
- False positives: if I look at the past and the 10 predictions I made on taking an umbrella and actually took one, how many did I get wrong? Similarly, there can be false negatives, real positives and real negatives. In short, it all depends on what data we use to calculate accuracy or precision.
- Accuracy: the percentage from calculating how many times I really got it right and stayed dry from every 10 times I go out and take an umbrella. It measures how reliable my model is when making forecasts.
- Model monitoring: this may be one of the most important terms as it attempts to decide when a model stops being reliable and what I have to do at that moment. In relocating to the tropics, I have to replace one model for another, I need to generate results with both and compare them one day to the next until I can prove that the new one is better.
This entire set of neat terms – and lots of others besides – attempt to express trust models in the world that I can use in forecasts to take decisions and describe the reasons and times where this trust is lost.
Without going into the world of data, it is important to highlight that this is the essential basis for decisions to be good ones. It is therefore important to know what is termed the predictability of a variable. That is, “hip pain” is a predictor variable while the pain is not enduring or has never existed, where it stops being predictive. In short, finding the right information, collecting it, processing it “as it should be”. It is essential that all possible types of information be represented (bias) so that we can be at peace with our decisions based on forecasts.
Who's who?
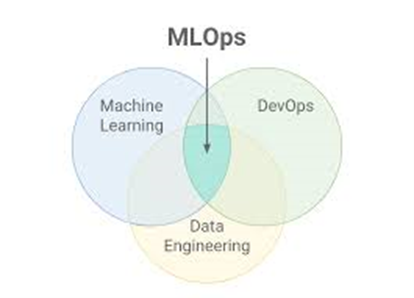
After explaining concepts, let's move on to the industrial sphere:
--> DataOps is responsible for collecting data, automating their processing and preparing them for decision-making. It is based on making the best data available in the best possible way.
--> MLOps is responsible for generating the grounds, applying them, calculating possibilities and assessing the reliability of the result. It is based on using data in the best possible way.
Both attempt to contribute in time and manner to provide the business with the best possible data to make decisions. Every discipline generates enough material for an article; here we will focus on our efforts with MLOps.
MLOps focuses on the operationalisation (DevOps) of automatic learning models (ML). In this sense, both concepts are combined under a single paradigm. Although the theory seems simple, this is not the case in practice.
Over the last few years, many software developments have come into production. Huge amounts of articles, methodologies, systematics and tests on how to do this have been generated; therefore, we could say that the DevOps world is a mature one with:
1. Naming standardisations
2. Pipelines for deployment
3. Software test definitions
4. Testing models
5. Monitoring models
Software is developed, deployment pipelines configured, standard tests performed and, in going through different environments, it comes into production. Unless monitoring brings up any error or new evolutions are developed, neither the software nor the work model will change.
A new tenant arrives in the world where the main mission of data scientists (DS) is not to develop software but understand data and come up with new insights. Thanks to this new component in the club, new ways of working appear and we need to find synergies. In this context, the new DataOps and MLOps disciplines arise with new profiles: Data Engineer and ML Engineer.
The challenge
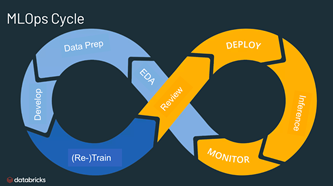
The challenge faced by these new profiles is to combine elements in a new paradigm:
DevOps is a rigid world that always tries to maintain operations under control, believing that it is possible establish all conditions beforehand, i.e. defined software for the same input will always produce the same output.
Data and ML is a changing world with huge evolutions that does not seek software stability but rather to generate new values.
Focusing on MLOps, the mission of an ML Engineer is to define how these worlds should coexist. To do this, they need knowledge in software engineering, ML and Ops.
They will be:
• Software engineers who have learnt about ML models and are able to automate them.
• DS who have acquired software development principles, design software and are able to automate models.
What's involved in ML
- Data, regardless of how they are generated. We should always be aware of how the data we use to make decisions vary.
- Algorithms, how data are processed to train them.
- Software, the process that defines the flow (pipeline) produced to generate the prediction.
- Model, the result of applying the algorithm in a pipeline to the data and which will be used to generate forecasts.
- Monitoring, how well the model behaves in relation to input data and real results.
Life cycle
We set out the necessary basis for ML above. Let’s see how a model was created and put into production to date.
The request
A sales unit wants to launch a campaign for a free umbrella if you open an account on a rainy day, and wants to have enough umbrella stock. In order to calculate the units they will need to make, they request a forecast of rainy days over the next 6 months, starting from January. The distribution will be generated daily, based on the weather forecast for the following day.
Development/experimentation
This stage focuses on input data, the algorithm and the model, largely ignoring the software and monitoring.
We get the request and need to have the model ready in production on 01 January.
- In order to calculate the average number of rainy days in the first 6 months of the year, we use historical data and with statistical methods, make an approximate forecast of rainy days and account sign-ups on rainy days. An approximate stock is generated, rounding up.
- In order to generate the distribution share, a predictive model will be generated based on time series, weather forecast, visits to branches on raining days, likelihood of sign-ups, etc.
It should be stated that the experimentation phase is largely dependent on historical data, meaning we need to ensure that this stage uses data that faithfully represent production data distribution.
In order to solve the second part, where we want to generate the predictive model, we set a work methodology:
- We prepare the training data for the model with historical data with which we already know sign-ups on rainy days.
- We take a representative section of the data for training and the rest we leave for validating the results.
- We enter the data in an algorithm that generates learning.
- From the data we reserved, we remove the component of whether there was a sign-up or not, pass them through the learning result and generate a forecast.
- We contrast the learning results with the real ones and generate a value that indicates the model’s reliability.
This process is repeated until a sufficiently good reliability indicator is attained so as to move forward with the process, i.e. until we are fairly sure that we are not going to confuse the amount of umbrellas we forecast will be needed for the next day.
Industrialisation
This stage focuses on software and monitoring. It aims to standardise so that it is repeatable, automatable, scalable, monitorable, maintainable, etc.
Unlike in experimentation, data dependence is minimal – it is merely necessary to ensure the data travel in line with the defined flows without generating unexpected errors.
Starting from the experiment that was approved in the previous stage, and under the parameters set by the DS, a software development process starts.
- Understanding the flow.
- Implementing the training flow.
- Implementing the prediction flow.
- Implementing the monitoring flow.
- Implementing the retraining logic.
- Implementing the production readiness logic.
- Integrating the data monitoring and models.
In order to conclude the development stage, we need to verify that all components play their role when they are necessary and that the obtained results are the expected ones.
Where all of the above is OK, the data, monitoring, software, model, etc. can be put into production.
Production
Let’s assume that everything is perfect and we manage to put it into production for 01 January. We will have in production:
- Software that is stable and able to generate a forecast based on input data.
- Software that is stable and which, based on an order, is able to generate a new version of the model with the same algorithm that learns from the new data that have been generated, i.e. it changes how it thinks.
- Software that is stable and able to compare forecasts with real data and generate comparative metrics.
- Software that is stable and able to measure when the data we use to predict and the results are drifting from what is expected.
Since the process is run daily, firstly we need to assess whether the forecasts and reality are sufficiently close, i.e. if I can continue to reach the conclusions that I did before. If this is not the case, it will be due to boundary conditions having changed. Consequently, we will need to launch a request to generate a new model and validate whether it will offer better forecasts than the current one. If the answer is yes again, one will replace the other and the change be recorded.
Curiously, all these modifications have taken place under the paradigms set by DevOps: “Software is developed, deployment pipelines configured, standard tests performed and, in going through different environments, it comes into production. Unless monitoring brings up any error or new evolutions are developed, neither the software nor the work model will change.”
Conclusions
The maturity of organisations comes from the fluidity in implementing life cycles. The role of ML Engineers is to introduce this new paradigm within organisations. Therefore:
- They should provide the DS with inherent knowledge and mechanisms for software life cycles that shorten the industrialisation stage.
- They should contribute tools enabling DS to focus on their developments without having to get involved in the world of software engineering although, in turn, they follow best practice set for it.
- They should provide DevOps with inherent knowledge and mechanisms through which the stability of software put into production is ensured.
- They should contribute tools enabling DevOps to focus on operations without having to get involved in the world of AI although, in turn, they follow best practice set for it.
Uncertainty is the worst enemy of evolution. Would you be willing to get into a self-driving car? Our mission is to contribute reliability and generate a friendly environment in all areas, and for industrial environments to also enable software to be autonomous.
Let me ask you this: will you head out with an umbrella tomorrow?
What do we do at CaixaBank Tech?
We are joining the future of ML by industrialising and incorporating industry standards, and generating our own frameworks that respect current ML rules and ensure adaptability to future regulatory and ethical frameworks. In the area of Advanced Analytics at CaixaBank Tech, we are seeking to generate a scalable, maintainable and sustainable work framework that minimises our footprint through optimising our processes.
tags:
share:


