





18/03/2023
As most of you will know, Spark is a framework created to process large amounts of data in a distributed way. Additionally, you can use three different languages (Scala, Java and Python). In order to achieve this, we need a cluster. What tool should we turn to?
In the beginning...
Spark could be run in three different ways:
- Independent cluster
- This does not need a resource administrator, just a Spark installation in each node.
- Mesos
- A cluster administrator runs in each node. It manages communication between controllers and worker nodes through API, and administers resources and task scheduling.
- YARN
- An Apache Hadoop component that programs jobs in a cluster. It also manages big data application resources.
Nowadays, the most common configuration is to use Spark with YARN. However, something has changed since Spark 2.3.x…
The cloud
Everybody is aware of the main aim of the process to shift to the cloud: saving lots of money spent on infrastructure. Initially, all companies dived in to “only pay for what’s needed”.
The shift to the cloud process offers many advantages to businesses: it boosts innovation, supports developments shared with third parties and makes investments in infrastructure more efficient, since you only pay for what you need.
In terms of Spark, the shift to the cloud seems to be a good solution as most applications are batch processed. In other words, the applications start and end in a time lag. Therefore, if hardware is purchased to run all Spark jobs, the infrastructure will likely not be 100% in use the entire time.
If we only have the independent cluster, Mesos and YARN, how do we deploy Spark in K8s?
That's where Spark 2.3 comes in
It is the first version of Spark to allow native K8s implementations. The controller is created with a dispatch from Spark to then generate the implementers.
But what type of dispatches does Spark have?
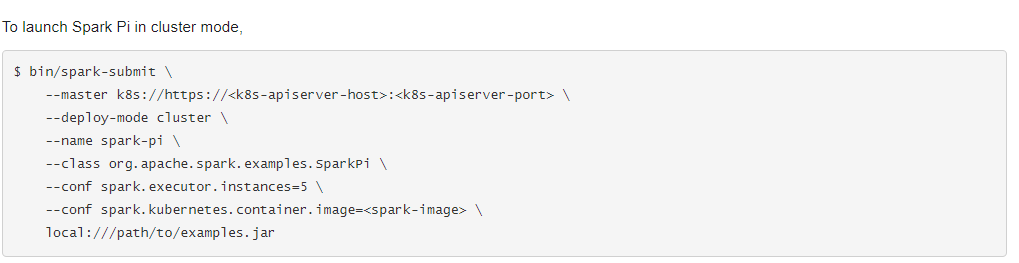
This image has been taken from a Spark 2.3.0 master copy running in K8s. We can imagine how hard it would be to find an error when working like this.
Native Spark architecture
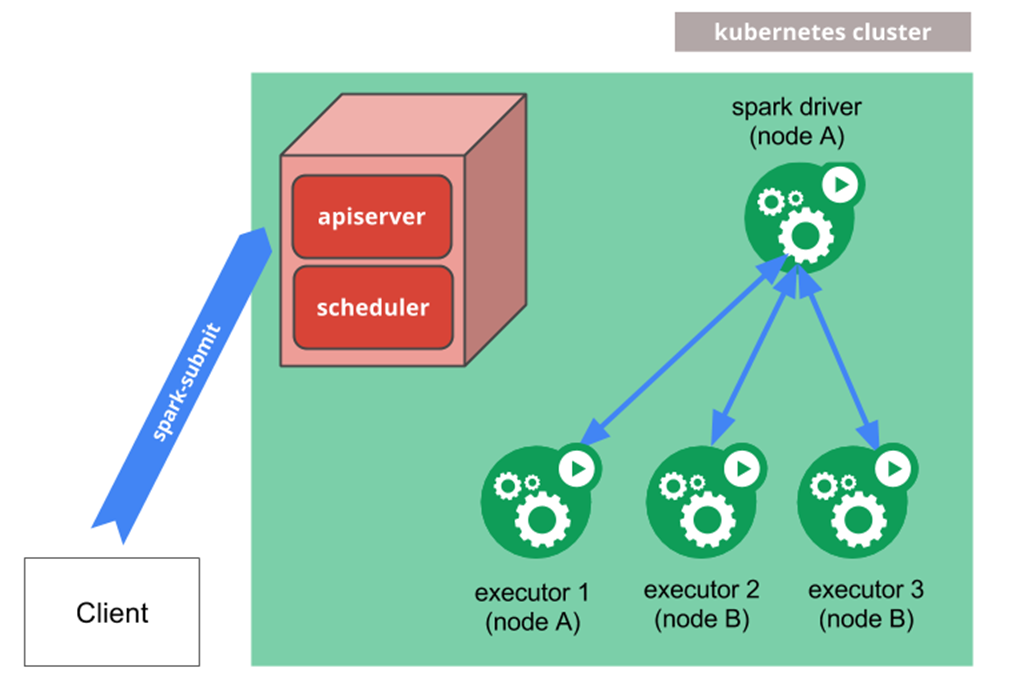
Here's where Spark Operator comes in
Now, Google comes to the rescue with a beta version of the product: Spark Operator. It introduces a new way to work with Spark in K8s, making it a “Kubernetes compatible” environment.
With the native method (Spark dispatch), you had to specify the host of the API server and the port in the command line.
In contrast, with Spark Operator we go into the K8s universe. Service accounts, role association, etc. need to be created, as well two new objects in K8s called SparkApplication and ScheduledSparkApplication.
Spark Operator solution architecture
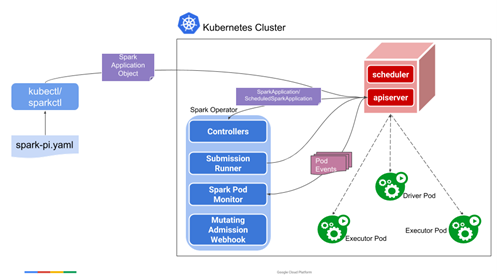
Here we have an example of the “spark-pi” process with Spark Operator. It is possible to run it with a kubectl command like any other K8s object once it is installed in the K8s cluster. To install this operator in a K8s environment, you only need to follow the documentation for the Spark Operator tool.
Want to know more? Don’t worry. Native Spark 3.x.x and Spark Operator 3.x.x are coming soon!
tags:
share:
