



19/05/2022
Como la mayoría de vosotros sabréis, Spark es un marco que se creó para procesar una gran cantidad de datos de forma distribuida. También se puede escribir en tres lenguajes diferentes (Scala, Java y Python). Para lograrlo, necesitamos un clúster, y ¿a qué herramientas podemos recurrir?
Al principio…
Spark podía ejecutarse de tres maneras diferentes:
- Clúster independiente
- No necesita ningún administrador de recursos, sino solo una instalación de Spark en cada nodo.
- Mesos
- Se ejecuta un administrador de clúster en cada nodo. Gestiona la comunicación entre controladores y nodos worker a través de API y administra los recursos y la programación de tareas.
- YARN
- Un componente Apache Hadoop que programa los trabajos en un clúster. También gestiona los recursos de aplicaciones de big data.
Hoy en día, la configuración más habitual es usar Spark con YARN, pero desde Spark 2.3.x algo ha cambiado…
La nube
Todo el mundo conoce el objetivo principal del proceso de nubificación: ahorrar gran parte del dinero que se gasta en infraestructuras. En un primer momento, todas las empresas se movilizaron para lograrlo, para así «pagar solo por lo que se necesita».
El proceso de nubificación ofrece muchas ventajas a las empresas: potencia la innovación, facilita desarrollos compartidos con terceros y, además, hace más eficientes las inversiones en infraestructuras, porque se paga solo por lo que se necesita.
Por lo que respecta a Spark, la nubificación parece una buena solución porque la mayoría de las aplicaciones son procesos por lotes. Es decir, estas aplicaciones comienzan y terminan en un lapso de tiempo. Por lo tanto, si se compra el hardware para poder ejecutar todos los trabajos de Spark, probablemente no se estará usando el 100 % de la infraestructura todo el tiempo.
Si solo contamos con el clúster independiente, Mesos y YARN, ¿cómo desplegamos Spark en K8s?
Para eso llega Spark 2.3
Se trata de la primera versión de Spark que admite implantaciones nativas de K8s. El controlador se crea con un envío de Spark y después genera los ejecutores.
Pero ¿qué tipo de envíos de Spark tenemos?
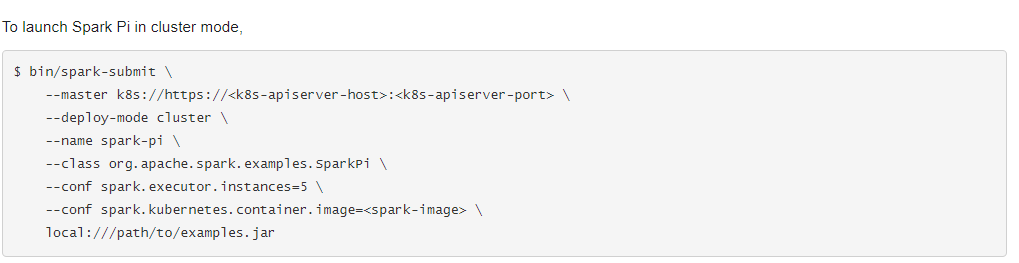
Esta imagen se ha sacado de un Spark 2.3.0 original ejecutándose en K8s. Podemos imaginarnos lo difícil que sería encontrar un error cuando se trabaja así.
Arquitectura nativa de Spark
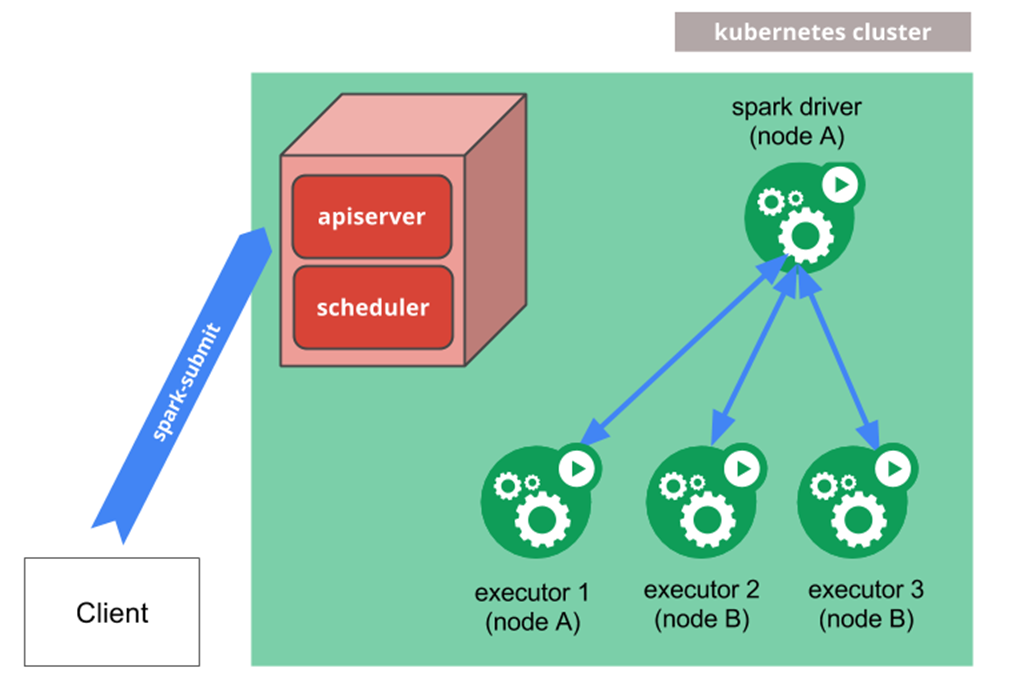
Aquí es donde aparece SparkOperator
Ahora, Google acude al rescate con una versión beta de este producto: Spark Operator. Introduce una nueva forma de trabajar con Spark en K8s, convirtiéndolo en un entorno «compatible con Kubernetes».
Con el método nativo (envío de Spark), había que especificar el host del servidor API y el puerto en la línea de comandos.
En cambio, con Spark Operator nos adentramos en el universo de K8s. Deben crearse las cuentas de servicio, la vinculación de roles, etc., así como dos nuevos objetos en K8s llamados SparkApplication y ScheduledSparkApplication.
Arquitectura de la solución Spark Operator
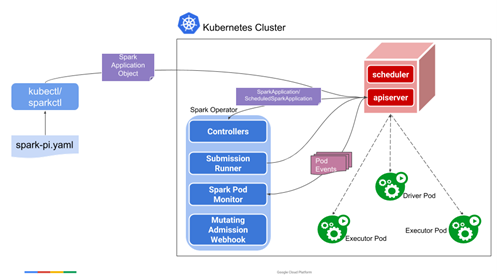
Aquí tenemos un ejemplo del proceso «spark-pi» con Spark Operator. Es posible ejecutarlo con un comando kubectl como cualquier otro objeto de K8s una vez que esté instalado en el clúster K8s. Para instalar este operador en un entorno K8s, solo hay que seguir la documentación de la herramienta Spark Operator.
¿Quiere saber más? No te preocupes. Pronto vendrán Spark 3.x.x y SparkOperator 3.x.x nativos!
tags:
Comparte:
