



19/05/2022
Com la majoria de vosaltres sabreu, Spark és un marc que es va crear per a processar una gran quantitat de dades de forma distribuïda. També es pot escriure en tres llenguatges diferents (Scala, Java i Python). Per a aconseguir-ho, necessitem un clúster, i a quines eines podem recórrer?
Al principi…
Spark podia executar-se de tres maneres diferents:
- Clúster independent
- No necessita cap administrador de recursos, només una instal·lació de Spark en cada node.
- Mesos
- S’executa un administrador de clúster en cada node. Gestiona la comunicació entre controladors i nodes worker a través d’una API i administra els recursos i la programació de tasques.
- YARN
- Un component Apatxe Hadoop que programa els treballs en un clúster. També gestiona els recursos d’aplicacions de Big Data.
Avui dia, la configuració més habitual és utilitzar Spark amb YARN, però des d’Spark 2.3.x alguna cosa ha canviat…
El núvol
Tothom coneix l’objectiu principal del procés de cloudificació: estalviar gran part dels diners que es gasta en infraestructures. En un primer moment, totes les empreses es van mobilitzar per a aconseguir-lo, per a així «pagar només pel que es necessita».
Pel que respecta a Spark, la cloudificació sembla una bona solució perquè la majoria de les aplicacions són processos per lots. És a dir, aquestes aplicacions comencen i acaben en un lapse de temps. Per tant, si es compra el maquinari per a poder executar tots els treballs d’Spark, probablement no s’estarà usant el 100% de la infraestructura tot el temps.
Si només comptem amb el clúster independent, Mesos i YARN, com despleguem Spark en K8s?
Per a això arriba Spark 2.3
Es tracta de la primera versió d’Spark que admet implantacions natives de K8s. El controlador es crea amb un enviament d’Spark i després genera els executors.
Però quin tipus d’enviaments d’Spark tenim?
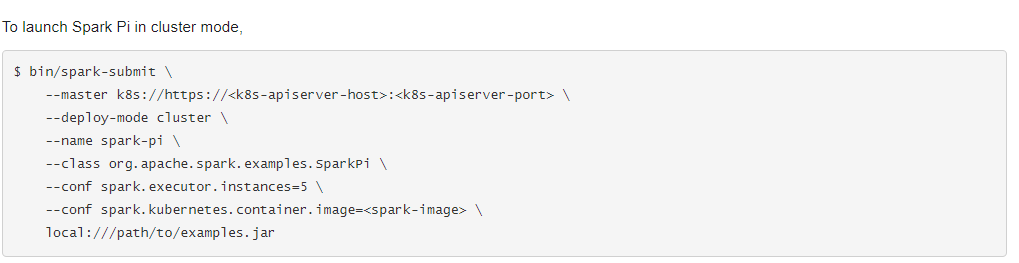
Aquesta imatge s’ha tret d’un Spark 2.3.0 original executant en K8s. Podem imaginar-nos el difícil que seria trobar un error quan es treballa així.
Arquitectura nativa d’Spark
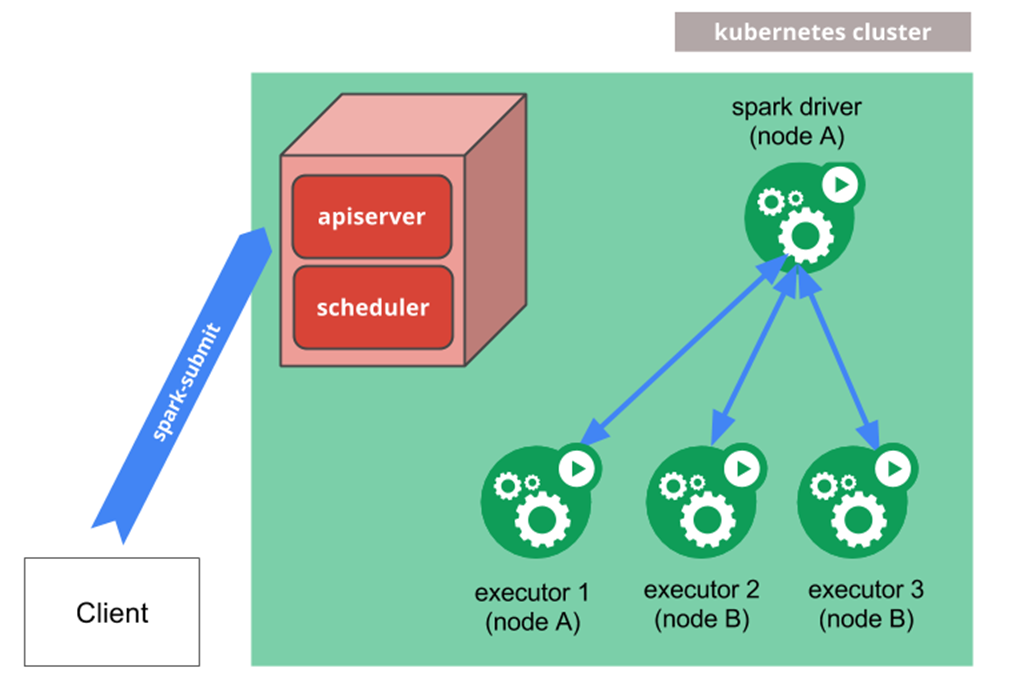
Aquí és on apareix SparkOperator
Ara, Google acudeix al rescat amb una versió beta d’aquest producte: Spark Operator. Introdueix una nova manera de treballar amb Spark en K8s convertint-ho en un entorn «compatible amb Kubernetes».
Amb el mètode natiu (enviament d’Spark), calia especificar el host del servidor api i el port en la línia de comandos.
En canvi, amb Spark Operator ens endinsem en l’univers de K8s. Han de crear-se els comptes de servei, la vinculació de rols, etc., així com dos nous objectes en K8s anomenats SparkApplication i ScheduledSparkApplication.
Arquitectura de la solució Spark Operator
Aquí tenim un exemple del procés «spark-pi» amb Spark Operator. Es pot executar amb un comandament kubectl com qualsevol altre objecte de K8s una vegada que estigui instal·lat al clúster K8s. Per instal·lar aquest operador en un entorn K8s, només cal seguir la documentació de l’eina Spark Operator.
Vols saber-ne més coses? No t’amoïnis. Aviat vindran Spark 3.x.x i SparkOperator 3.x.x natius!
tags:
Comparteix:
